 |
| Integer division, here called div_rem, takes two arguments and produces two results, a quotient and remainder, yet is certainly a function. |
(Even common nomenclature is confusing and/or inadequate for this discussion. "Multi-result function" sometimes refers to functions which may produce any one of a number of different results for the same inputs/arguments -- in other words, not functions at all! Sometimes the term "output" is used instead of "result" for the situation here, and "result" is used to refer to the actual instance (e.g. data value) being produced. Here, I use the term "result" as analogous to "argument" -- i.e. formally referring to a completely independent part of the output from (vs input to) a function application, without referring to the data fulfilling it, but there's no standard common name for this, as far as I can tell.)
What would composition between applications of multi-result functions look like? Unlike the single result case, it is not generally possible in a 1D or 2D textual representation to have each application adjacent to both any other applications providing its arguments (from their results) and those accepting its results (as their arguments). So, let's start by throwing off the strictures of sequential text, organizing the applications more loosely, such as in the 2-dimensional plane (e.g. a sheet of paper), representing each application by, say, a circle labeled with the name of the function, not necessarily physically adjacent to their upstream or downstream applications.
Then I'll represent each argument associated with each of those circles with, say, an arc (i.e. line segment) from the circle, as in the div_rem diagram above. Since we have lost the identification of these arguments that comes with their textual ordering, I now need to uniquely label each of those arcs with a number or name, so the function knows which is which. And, there's no reason not to represent results in exactly the same way, also with uniquely labeled arcs. I'll differentiate arguments from results with arrowheads on those arcs -- toward the circle for arguments, away from the circle for results.
So far, this looks somewhat like the beginning of a traditional visual dataflow model/graph. In those, result and argument arcs of different applications would be associated pairwise ("hooked up" or united in some way), so that data is considered to "flow" from the result of one application to the argument of the other. There might even be some sort of junction/bifurcation, to allow a single result arc to connect to multiple argument arcs.... and perhaps even multiple results to a single argument.
Such approaches beg questions like: Is it now possible/"legal" to produce multiple results on a single arc, to collect there (e.g. queue up) until consumed? Or, as a special case of that, for a single function application to produce multiple results on a single arc, to potentially be consumed by different downstream applications? And if multiples are allowed, does each datum stay individual, or do they merge together into a stream? And, when an arc does split, does the "actual" result datum go only to the first argument branch trying to "consume" it, or to all the argument branches? But it wasn't our intent to create more questions, or to make the arcs constructs in themselves with their own semantics, just to associate arguments and results.
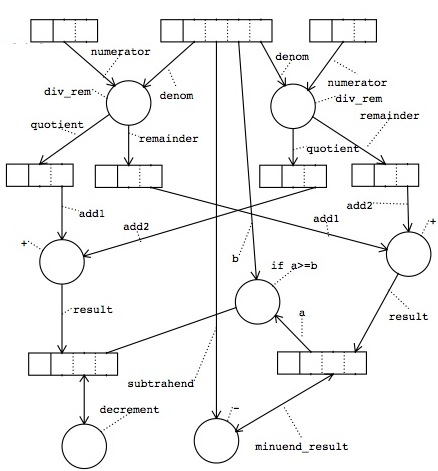 To simplify and clarify, I'll instead toss a bunch of rectangles into this 2D diagram, which I'll call resources ("variables" if you like), and declare that each is capable of holding one datum. Now, instead of tying argument and result arcs directly to one another as in dataflow, I'll tie them to these resources. This is clearer: If an argument arc is tied to the resource, the entire content on the resource is used (as the "actual" for the "formal" argument) when evaluating the function application, and if a result arc is tied to the resource, the new content of the resource (all of it) becomes that result of the function application. I'll also define the initial content on each of these resources, to ensure everything is well defined to start out.
To simplify and clarify, I'll instead toss a bunch of rectangles into this 2D diagram, which I'll call resources ("variables" if you like), and declare that each is capable of holding one datum. Now, instead of tying argument and result arcs directly to one another as in dataflow, I'll tie them to these resources. This is clearer: If an argument arc is tied to the resource, the entire content on the resource is used (as the "actual" for the "formal" argument) when evaluating the function application, and if a result arc is tied to the resource, the new content of the resource (all of it) becomes that result of the function application. I'll also define the initial content on each of these resources, to ensure everything is well defined to start out.
But which application(s) can/should evaluate at any one time? Functions (or functional models) are often held forth as embodying no concept of control flow, but in order for them to achieve their full power, just as in imperative approaches, they must have a way to selectively suppress evaluation, or play tricks to accomplish the same end (such as to selectively make evaluations idempotent). The most common approach in functional languages is lazy (or "on demand") evaluation to suppress evaluation of function arguments until they are needed (such as through evaluation or lambda operations). Dataflow models may use variables which transition between empty/undefined or full/defined states to control whether upstream or downstream evaluations can occur.
 I'll generalize these traditional approaches into a simple unified system: In addition to the mutable (i.e. changeable) content (aka content state) of each resource, I'll also associate a mutable so-called control state with the resource, which is simply an indication (in some form) of which of the function applications, bound to the resource, are currently allowed to evaluate. A function application can only evaluate if the control state of all of its resources (i.e. those bound to all of its arguments or results) says it's OK to do so. And when it does evaluate, it not only produces (deterministically, of course) new content state for the resources associated with its result arcs, it also produces (deterministically) a new control state to all of its resources -- those representing both arguments and results -- to indicate what can evaluate next. For simplicity, I'll consider control state as a color, and associate one or more permanent colors with each arc, shown on "access dots" at the end of the arc. So the evaluation rule becomes: A function application (circle) can only evaluate when the current (last assigned) control state (color) of each of its resources matches one of the access dots associated with it (on the argument or result arc). And just like content state, we'll define the initial control state of each resource, specifically as the color green, so that the starting condition is well defined.
I'll generalize these traditional approaches into a simple unified system: In addition to the mutable (i.e. changeable) content (aka content state) of each resource, I'll also associate a mutable so-called control state with the resource, which is simply an indication (in some form) of which of the function applications, bound to the resource, are currently allowed to evaluate. A function application can only evaluate if the control state of all of its resources (i.e. those bound to all of its arguments or results) says it's OK to do so. And when it does evaluate, it not only produces (deterministically, of course) new content state for the resources associated with its result arcs, it also produces (deterministically) a new control state to all of its resources -- those representing both arguments and results -- to indicate what can evaluate next. For simplicity, I'll consider control state as a color, and associate one or more permanent colors with each arc, shown on "access dots" at the end of the arc. So the evaluation rule becomes: A function application (circle) can only evaluate when the current (last assigned) control state (color) of each of its resources matches one of the access dots associated with it (on the argument or result arc). And just like content state, we'll define the initial control state of each resource, specifically as the color green, so that the starting condition is well defined.
This does create one confusion, however: If the same resource is used as both an argument and result, the function should know that so (at least) it won't assign a different control state to each. So, I'll rule out binding both an argument and result to a single resource, and instead create a new kind of arc (with arrows on both ends) that takes an argument from, and produces a result to, the same resource. Since it's one arc, it gets one new control state as a result of the evaluation. And since we now have arcs with arrowheads at one end or the other or both, I'll also allow "no data" arcs with no arrowheads -- i.e. which can restrict the evaluation of a function application (via its access dots) and which can produce a new control state to its resource, but which doesn't observe or affect the content state of the resource at all.
What I've just described is the meat of a computation model called F-Nets, short for Function Networks. There are a few other touch-ups, to ensure that the function declarations are abstract/modular enough to be applied in different contexts, and to provide a property called "predictability" for efficiency, but for the most part, it's just as described. It was my PhD dissertation, and it forms the basis for the Scalable Planning Language described in the book Scalable Planning: Concurrent Action from Elemental Thinking, and the above is a condensation of much of what is in Chapters 2 and 3 of that book. F-Nets is similar to many other models, including Petri Nets, Unity, dataflow, etc.
Are these multi-result functions really "functions"? How can they not be? Their results (both content and control state) are completely determined by their arguments. "But they can update resources, thwarting referential transparency", I hear you say. "And worse, their composition can potentially be nondeterministic, and (therefore) non-functional!"
While those statements are true, they are features available in this form of composition, and it is odd to fear or criticize one form of expression as being more powerful and flexible than another. F-Nets can be constrained to be deterministic, resources can be constrained to be defined only once, so referential transparency can be attained if that's important. But traditional function composition is simply not up to the task of representing complex combinations of multi-result functions, and/or representing nondeterminacy of any kind. F-Nets are. They also have an intuitive graphical representation that suits software engineering and component/coordination languages, and merges imperative, data flow, and functional approaches. They are fully formal, with both operational and axiomatic semantics. They are concurrent, portable, efficient. They are a valuable tool in planner's toolbox. Traditional functional composition is nice where it works: F-Nets are there for other cases.